
PyFlink Series (Part 3)
Back to: Part 2 (Basic Data Stream API Job with Custom Operators)
This will be our first job where we’re bringing in external dependencies to run.
The example project contains artifacts and convenience make commands to
help package our dependencies.
Within the lib folder, we have a pom.xml containing several dependencies for all the example jobs in this repository.
Of interest to this particular job is the kafka connector:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>3.2.0-1.19</version>
</dependency>To build the dependencies for running this and other examples, you can simply run:
make jar
This will use a Maven+Java Docker container to fetch all required dependencies and package them into a single “fat” jar.
You’ll here this fat jar sometimes called a shadowjar.
Define imports
from os import path, getenv
from pyflink.common import SimpleStringSchema, WatermarkStrategy
from pyflink.datastream import (StreamExecutionEnvironment, RuntimeExecutionMode)
from pyflink.datastream.connectors.base import DeliveryGuarantee
from pyflink.datastream.connectors.kafka import (KafkaSource,
KafkaOffsetsInitializer, KafkaSink, KafkaRecordSerializationSchema)
Build the DAG
Setting up the DataStream environment. These could be standardized in a production system to be configured in a more modular way.
brokers = "localhost:9092" # Local kafka running on docker-compose
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1)We’ll get into submitting jobs into a real Flink cluster later on, but for running locally we’ll need to tell Flink where our dependencies are. We set the following environment configuration to enable local running/debugging by manually adding the project’s shadow jar (location + classpath).
The shadowjar has all the connectors and additional Java dependencies built into a single jar.
if LOCAL_DEBUG:
jar_location = str(path.join(path.dirname(path.abspath(__file__)), "../lib/bin/pyflink-services-1.0.jar"))
env.add_jars(f"file:///{jar_location}")
env.add_classpaths(f"file:///{jar_location}")Flink uses the builder pattern for many things, here we use the KafkaSource builder to define our data source.
# Kafka source definition
source = (KafkaSource.builder()
.set_bootstrap_servers(brokers)
.set_topics("input_topic")
.set_group_id("stream_example")
.set_starting_offsets(KafkaOffsetsInitializer.earliest())
.set_value_only_deserializer(SimpleStringSchema())
.build())
# Build a Datastream from the Kafka source
stream = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")Similarly, the sink is defined using a builder.
# Kafka sink definition
sink = (KafkaSink.builder()
.set_bootstrap_servers(brokers)
.set_record_serializer(
KafkaRecordSerializationSchema.builder()
.set_topic("output_topic")
.set_value_serialization_schema(SimpleStringSchema())
.build()
)
.set_delivery_guarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build())Putting it all together, we connect the source into the sink and run our job:
def run():
brokers = "localhost:9092"
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1)
# To enable local running/debugging, we manually add the project's shadow jar that has all the connectors built in
if LOCAL_DEBUG:
jar_location = str(path.join(path.dirname(path.abspath(__file__)), "../lib/bin/pyflink-services-1.0.jar"))
env.add_jars(f"file:///{jar_location}")
env.add_classpaths(f"file:///{jar_location}")
# Kafka source definition
source = (KafkaSource.builder()
.set_bootstrap_servers(brokers)
.set_topics("input_topic")
.set_group_id("stream_example")
.set_starting_offsets(KafkaOffsetsInitializer.earliest())
.set_value_only_deserializer(SimpleStringSchema())
.build())
# Build a Datastream from the Kafka source
stream = env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
# Kafka sink definition
sink = (KafkaSink.builder()
.set_bootstrap_servers(brokers)
.set_record_serializer(
KafkaRecordSerializationSchema.builder()
.set_topic("output_topic")
.set_value_serialization_schema(SimpleStringSchema())
.build()
)
.set_delivery_guarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build())
# sink the Datastream from the Kafka source
stream.sink_to(sink)
env.execute("kafka-2-kafka")
if __name__ == '__main__':
run()We’re not doing anything too fancy here, essentially relaying events from one topic to another.
To test this job out, you’ll need a running Kafka cluster, as well as some mechanism to push events into the input_topic,
as well as a way to read the relayed events over on the output_topic.
You can use the example project’s docker-compose setup to start a standalone kafka cluster, as well as a UI to read and write events with.
To start the local services defined in the docker-compose file, simply run the following command from the console:
make services
Once everything is built and running, start the job:
python ./jobs/ds_app_kafka_kafka.pyand head over to http://localhost:8080/ui/clusters/local/all-topics?perPage=25.
You should see something like:
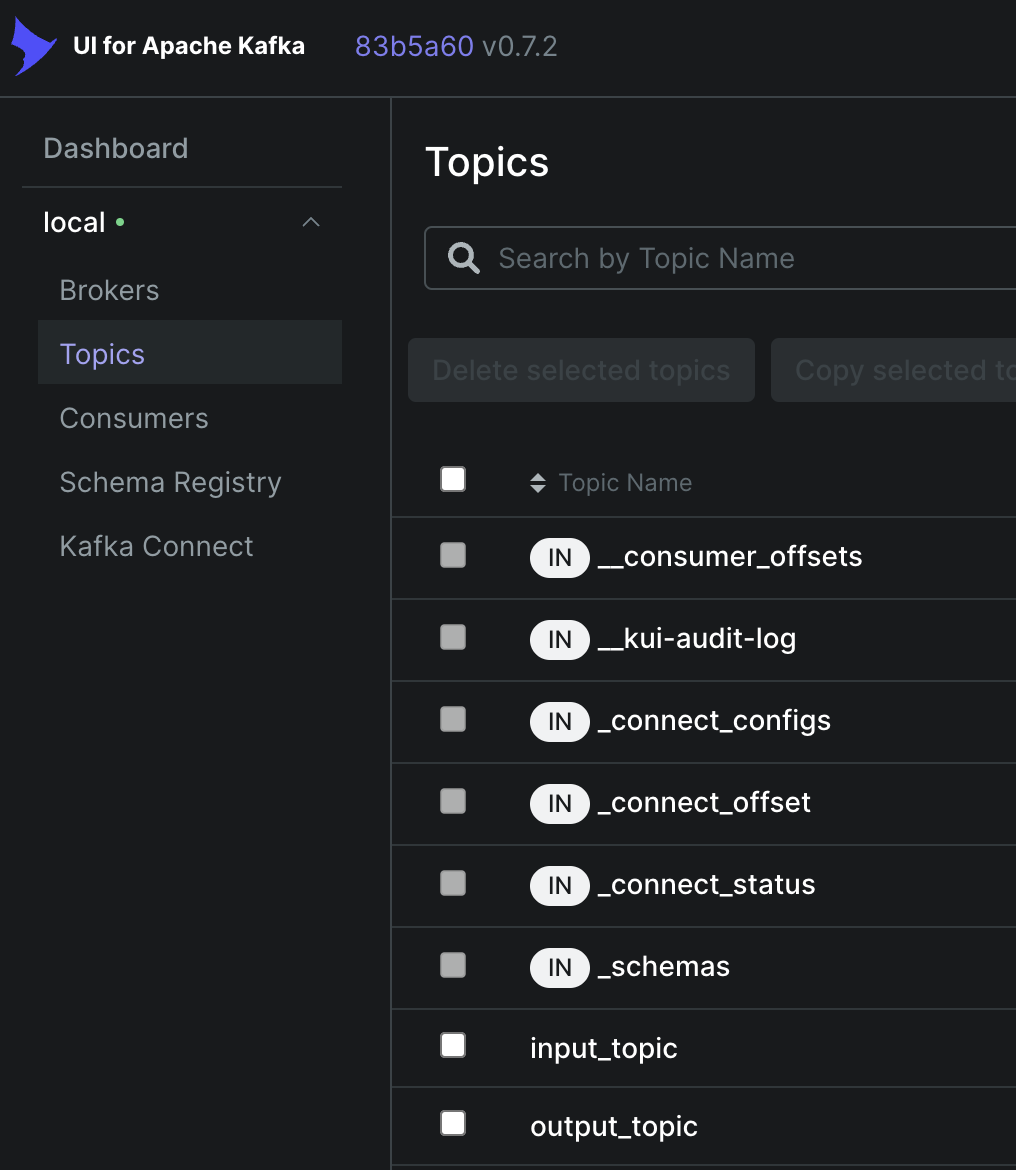
Click into the input_topic, and press Produce Message, then enter something into the value field:
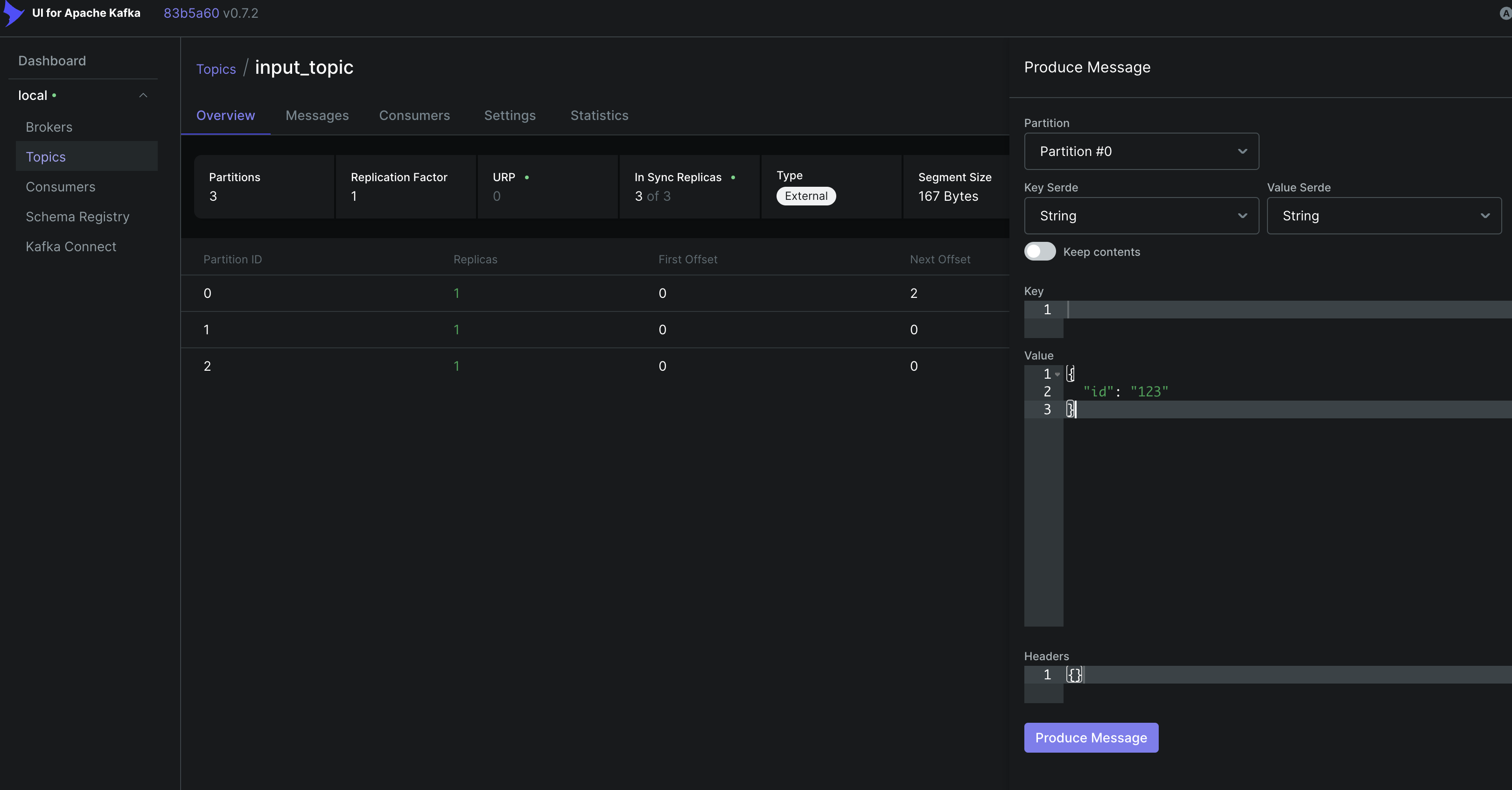 then hit the Produce Message button at the bottom of the form.
then hit the Produce Message button at the bottom of the form.
Your running pyflink job will pull the new message from the input_topic and push it to the output_topic in just a few
milliseconds.
You can confirm this by heading over to the output_topic in the kafka UI and clicking the messages tab:
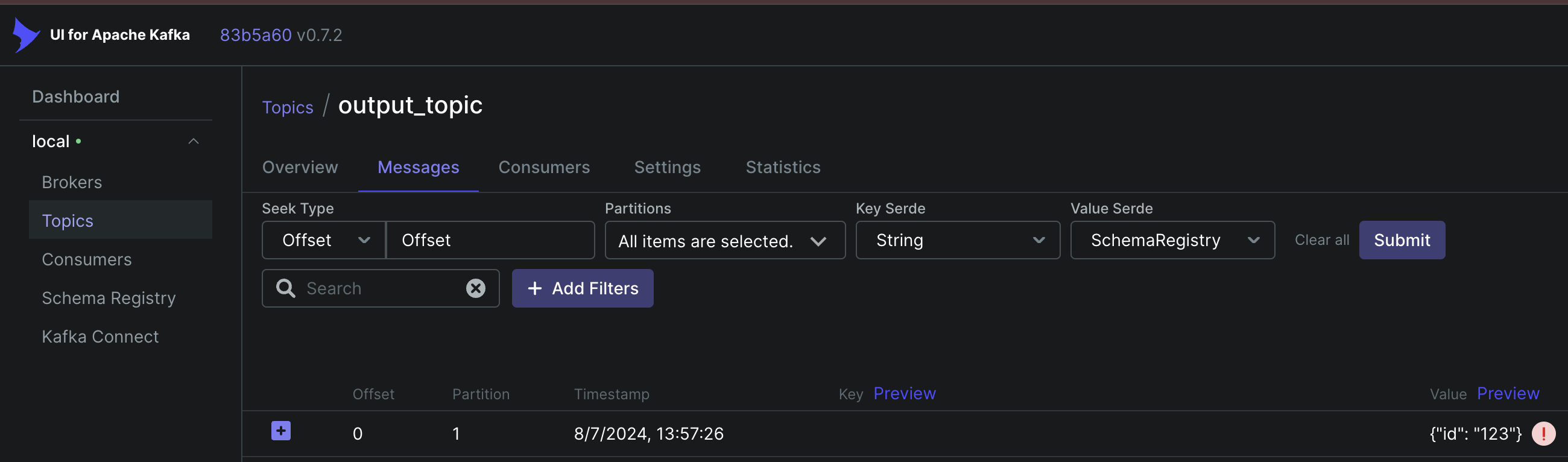
Congratulations, we’re now running PyFlink Datastream API jobs that are interfacing with external connectors!
Up next: Part 4 (Data Stream API Job with Local AWS Kinesis Source and Sink)