PyFlink Series (Part 1)
Basic Data Stream API Job
Define imports
from pyflink.datastream import StreamExecutionEnvironment, RuntimeExecutionModeBuild the DAG
def run():
# Build Execution environment and set some default configs for testing
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1)
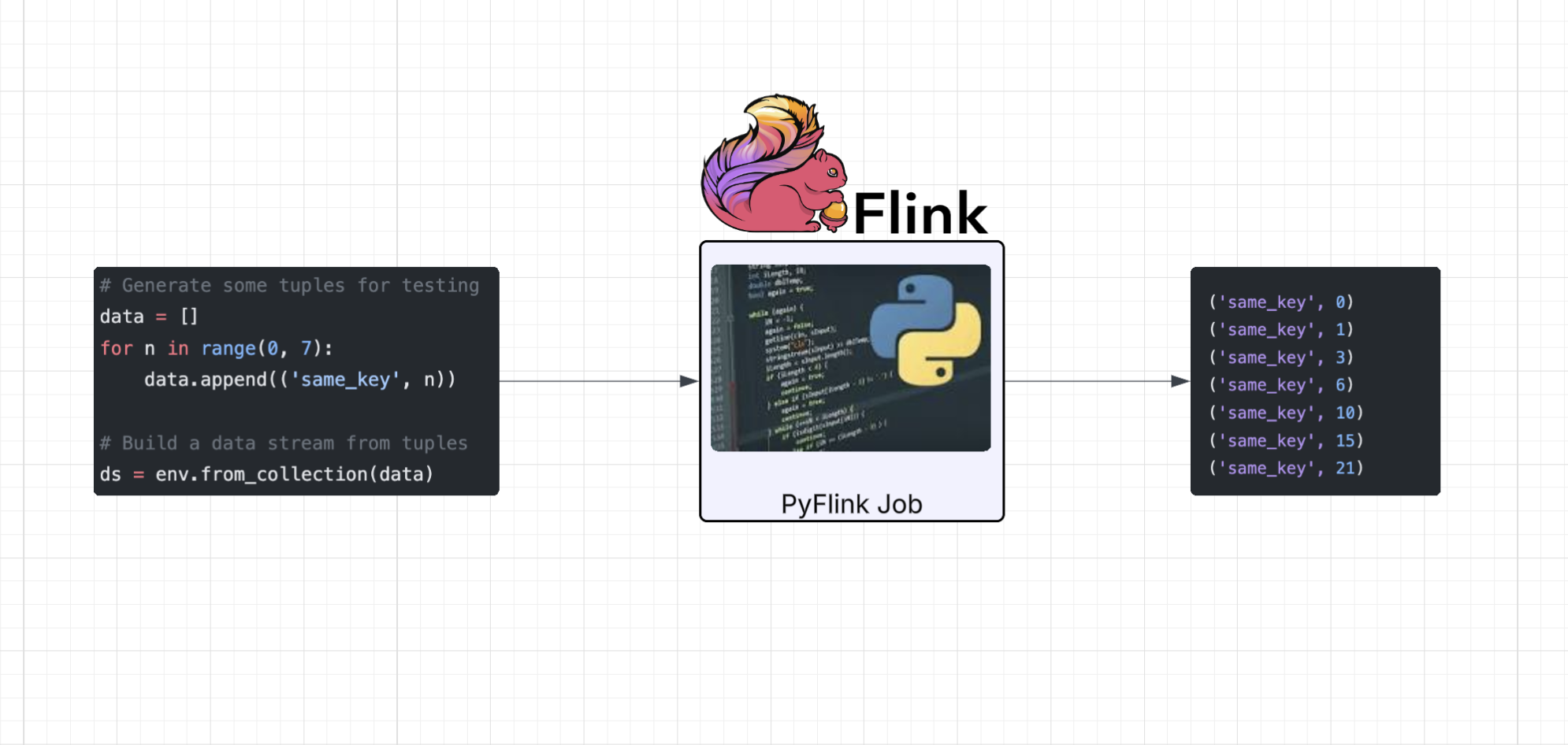
# Generate some tuples for testing
data = []
for n in range(0, 7):
data.append(('same_key', n))
# Build a data stream from tuples
ds = env.from_collection(data)
# We want to sum values, but that requires a keyed stream so we key it
ds = ds.key_by(lambda x: x[0])
# Next we chain the keyed stream into a summed stream, this is a stateful operation and translates our keyed stream
# back to a regular stream
ds = ds.sum(1)
# Here we're just using the in-built sink for STD::OUT to visualize the results
ds.print()
"""
FWIW - You'd normally just define your dag chaining the stream(s) together using the fluent interface,
I just broke it out above to devsplain it ;)
eg.
(env.from_collection(data)
.key_by(lambda x: x[0])
.sum(1)
.print())
"""
# This is what actually assembles the DAG and returns it to the JobManager so that it can run on a task slot.
env.execute("basic_datastream_job")For convenience, I like to wrap the DAG creation in a function, then I can call it locally using standard python:
if __name__ == '__main__':
run()If you’ve set up your dev environment correctly, you should see the following output when running your job as a python script:
('same_key', 0)
('same_key', 1)
('same_key', 3)
('same_key', 6)
('same_key', 10)
('same_key', 15)
('same_key', 21)As can be seen, the second element in the tuple is summed as each “event” passes through the DAG.
Up next: Part 2 (Basic Data Stream API Job with Custom Operators)