PyFlink Series (Part 2)
Back to: Part 1 (Basic Data Stream API Job)
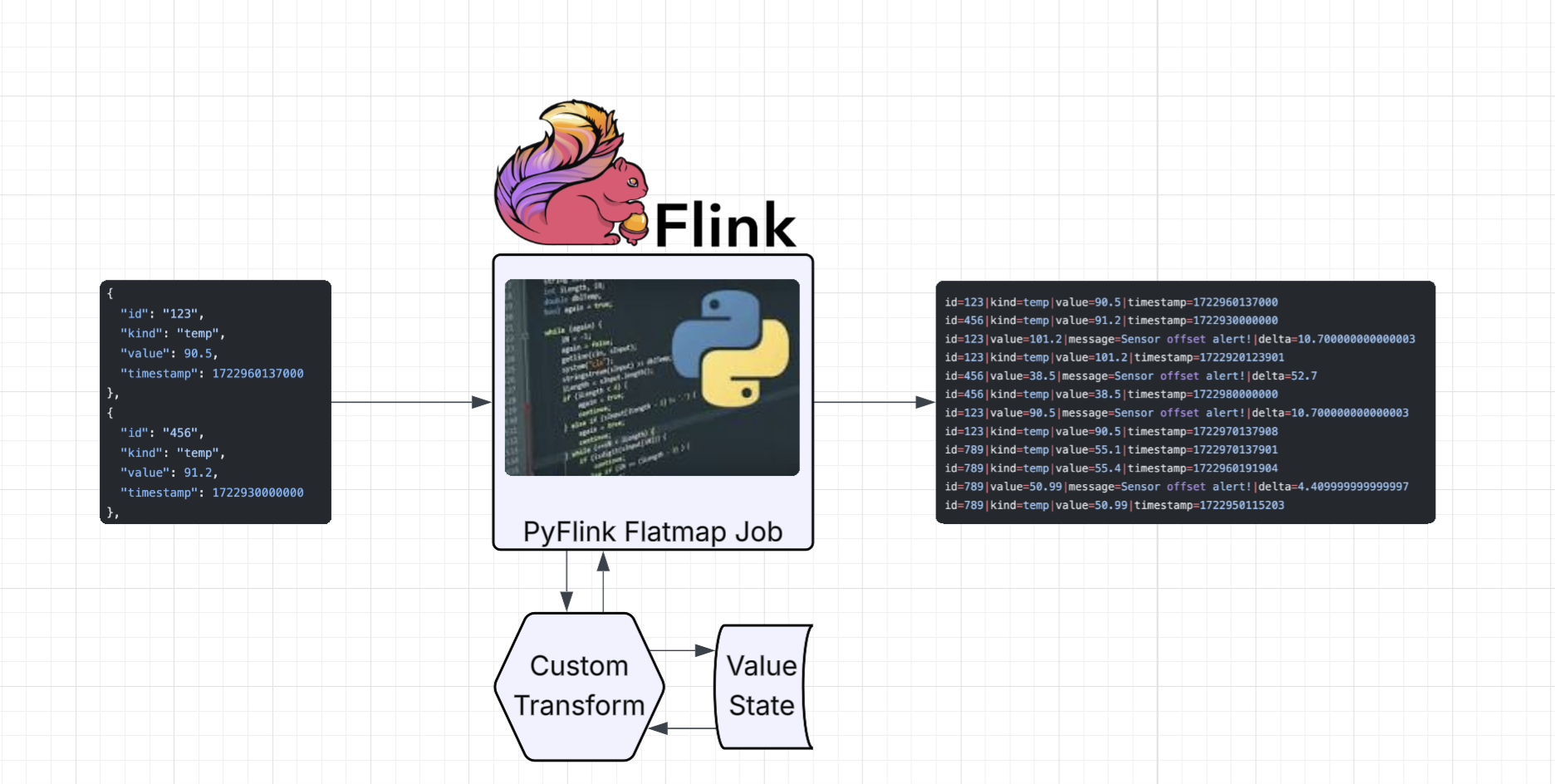
Basic Data Stream API Job with Custom Operators
In this example, we’ll simulate a stream of IoT sensor data that are tracking temperatures in our facility.
Test data
[
{
"id": "123",
"kind": "temp",
"value": 90.5,
"timestamp": 1722960137000
},
{
"id": "456",
"kind": "temp",
"value": 91.2,
"timestamp": 1722930000000
},
{
"id": "123",
"kind": "temp",
"value": 101.2,
"timestamp": 1722920123901
},
{
"id": "456",
"kind": "temp",
"value": 38.5,
"timestamp": 1722980000000
},
{
"id": "123",
"kind": "temp",
"value": 90.5,
"timestamp": 1722970137908
},
{
"id": "789",
"kind": "temp",
"value": 55.1,
"timestamp": 1722970137901
},
{
"id": "789",
"kind": "temp",
"value": 55.4,
"timestamp": 1722960191904
},
{
"id": "789",
"kind": "temp",
"value": 50.99,
"timestamp": 1722950115203
}
]Define imports
# Used to load test data (could also use Flink's in-built file loading connectors)
import json
import pathlib
from pyflink.common import Types
from pyflink.datastream import (StreamExecutionEnvironment, RuntimeExecutionMode, RuntimeContext
# Custom Operator Classes
MapFunction, FlatMapFunction )
#We're going to use state to detect anomalies
from pyflink.datastream.state import MapStateDescriptorDefine our Operators
Let’s say that our system uses a custom serialization format.
You could use a python lambda x: x for this, but for a more complete example we’ll override the underlying class.
This is especially useful if you’re going to share functions across jobs.
class SerializerMapFunction(MapFunction):
"""
Custom map function to format readings in a compact way
"""
def map(self, value):
record = '|'.join([k + '=' + str(v) for k, v in value.items()])
return recordNow we need a stateful function to track sensor value changes.
We need to access state here so we need to override something that derives from RichProcessFunction.
FlatMapFunction will be perfect for our task.
FlatMap works exactly as the monad you’d expect it to. For each element in, zero or more elements can be emitted out.
You just need to override the flat_map generator function.
class LookupKeyedProcessFunction(FlatMapFunction):
"""
Function to track keyed sensor readings and emit additional events when an anomaly is detected.
"""
def __init__(self):
# We can define our state here, but it won't be available until the `open` lifecycle function is called
self.lut_state = None
def open(self, runtime_context: RuntimeContext):
state_desc = MapStateDescriptor('LUT', Types.STRING(), Types.FLOAT())
# Here we can fully register this operator's state and pass in it's type definition
# (remember under the hood this translates into a Java object so it needs to be strongly typed)
self.lut_state = runtime_context.get_map_state(state_desc)
def flat_map(self, value):
# get a handle on state reference
lut = self.lut_state.get_internal_state()
# try to get the previously tracked value (and default to the current if one doesn't exist yet)
prev = lut.get(value.get("kind")) or value.get("value")
# calculate the diff
diff = abs(prev - value.get("value"))
if diff > 1:
# big diff :)
yield {'id': value.get("id"), 'value': value.get("value"), 'message': 'Sensor offset alert!', 'delta': diff}
# update the current state with this event's value
# notice how we are mapping by kind so we can track multiple sensor readings if we wanted to
self.lut_state.put(value.get("kind"), value.get("value"))
yield value
Build the DAG
Putting it all together in a job script. You can imagine that it might be nice to have a base class for defining jobs. Concerns such as resolving configurations, dependency injection, etc… could be streamlined with a Job module.
def run():
# Load the data from test file (this could also be done with Flink file connector)
data = json.loads(pathlib.Path(__file__).parent.joinpath('../generators/sensors.json').read_text())
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
env.set_parallelism(1)
(env.from_collection(data)
# group events by sensor `id`
.key_by(lambda x: x.get("id"), Types.STRING())
# check for anomalies
.process(LookupKeyedProcessFunction(), output_type=Types.MAP(Types.STRING(), Types.STRING()))
# use our custom serializer
.map(SerializerMapFunction(), output_type=Types.STRING())
.print())
env.execute("sensors")For now, we’ll keep things simple and run the job locally on the command line:
python ./jobs/ds_app_basic_custom_operators.py If you’re using an IDE like me (pycharm), you can set breakpoints within your operator code to help understand what’s going on.
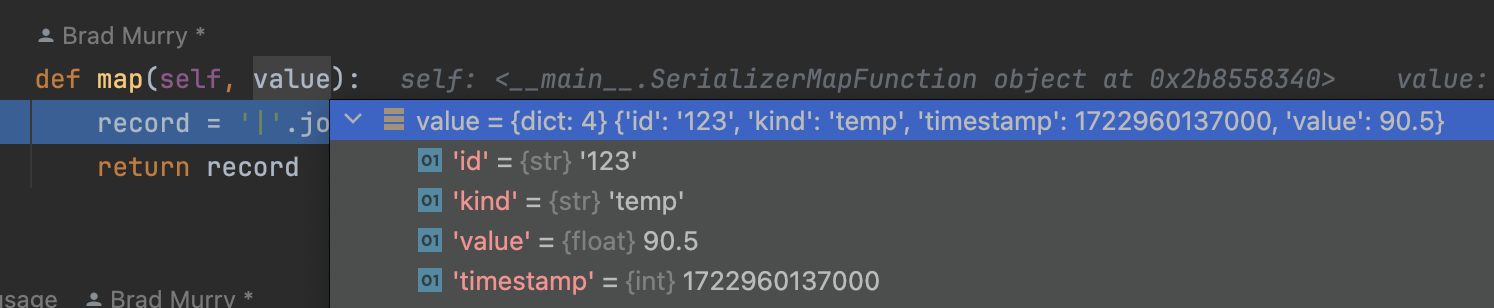
If you’ve set up your dev environment correctly, you should see the following output when running your job as a python script:
id=123|kind=temp|value=90.5|timestamp=1722960137000
id=456|kind=temp|value=91.2|timestamp=1722930000000
id=123|value=101.2|message=Sensor offset alert!|delta=10.700000000000003
id=123|kind=temp|value=101.2|timestamp=1722920123901
id=456|value=38.5|message=Sensor offset alert!|delta=52.7
id=456|kind=temp|value=38.5|timestamp=1722980000000
id=123|value=90.5|message=Sensor offset alert!|delta=10.700000000000003
id=123|kind=temp|value=90.5|timestamp=1722970137908
id=789|kind=temp|value=55.1|timestamp=1722970137901
id=789|kind=temp|value=55.4|timestamp=1722960191904
id=789|value=50.99|message=Sensor offset alert!|delta=4.409999999999997
id=789|kind=temp|value=50.99|timestamp=1722950115203Congratulations! You now have a functional data stream application that is stateful, can process events in flight as well as format the output using a custom serializer.
Checkout the DataStream API Operators documentation to learn more about Flink’s low level operators.
Up next: Part 3 (Data Stream API Job with Local Kafka Source and Sink)